Rollup architecture recommendations

Summary
At Modular Cloud, we see lots of rollups. Here are some thoughts I have put together for how I believe they should be built. I am thinking about this from the perspective of a cloud infrastructure provider. However, I would bet that anyone integrating with multiple rollups (i.e. people building dev tools and cross-chain protocols) would agree with most of these suggestions.
The problem with many rollup implementations today is that they have unnecessarily high storage requirements, don't always provide the data needed to those integrating with them, and are difficult to run. The changes suggested in this document reduce storage costs, provide rich context to integration partners, simplify the DevOps process, and ultimately enable web2 scale and performance.
In short, these are the suggestions:
- It should be possible to run the state transition function in isolation (not as part of a long-running process). When passing in data from the L1, it should connect to a database with some existing state and apply the state diff (based on the L1 data) to the DB.
- There should be a database adapter that allows you to swap out different KV database backends without breaking the codebase.
- Similar to the state transition function, RPC Methods (or other built-in APIs for querying state/data) should be stateless, short-lived functions that can be be executed in isolation (without needing to be exposed by the node's built-in web server). They should simply connect to the DB and return the result for the query.
Theory
You can think of a rollup as a wrapper around a state transition function
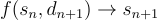
Where the previous state and new data from the L1 are fed into the function and the updated state is returned.
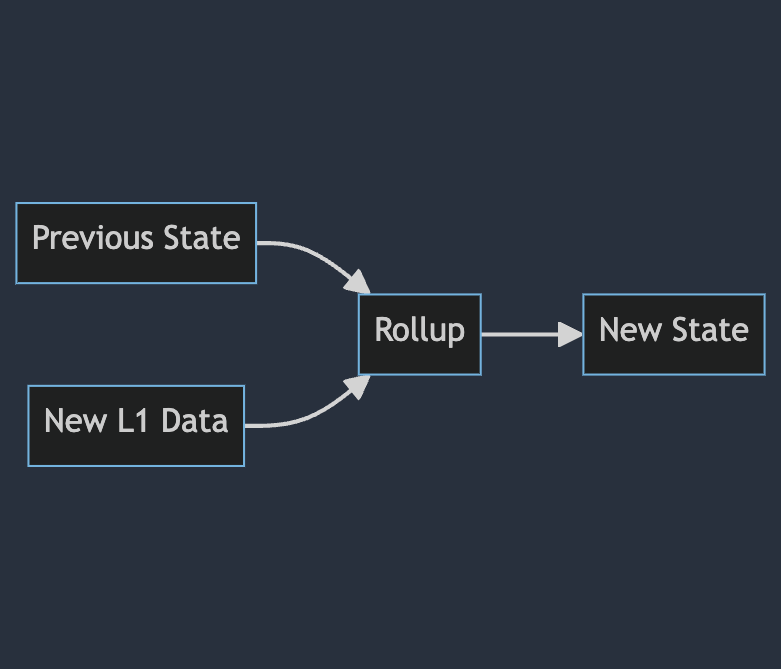
graph LR
A[Previous State] --> C[Rollup]
B[New L1 Data] --> C
C --> D[New State]
Further, I like to model it as an accumulation of state diffs
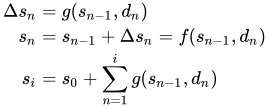
Which I think maps nicely to its implementation with a reducer
function rollup(s, d):
delta = g(s, d)
return s + delta
dataList = [d1, d2, d3, ..., di]
initialState = s0
latestState = reduce(deltaFunction, dataList, initialState)
Note: Shared sequencer, soft finality guarantees, and modular settlement layers make this more complex, but are do not change the underlying theory.
Current execution flow
Today, most rollups work by:
- Looping and checking the L1 for new data
- When it finds new data, sending it out an event to a channel or event stream
- Iterating on that event stream and writing the latest state and blockchain data to an embedded database
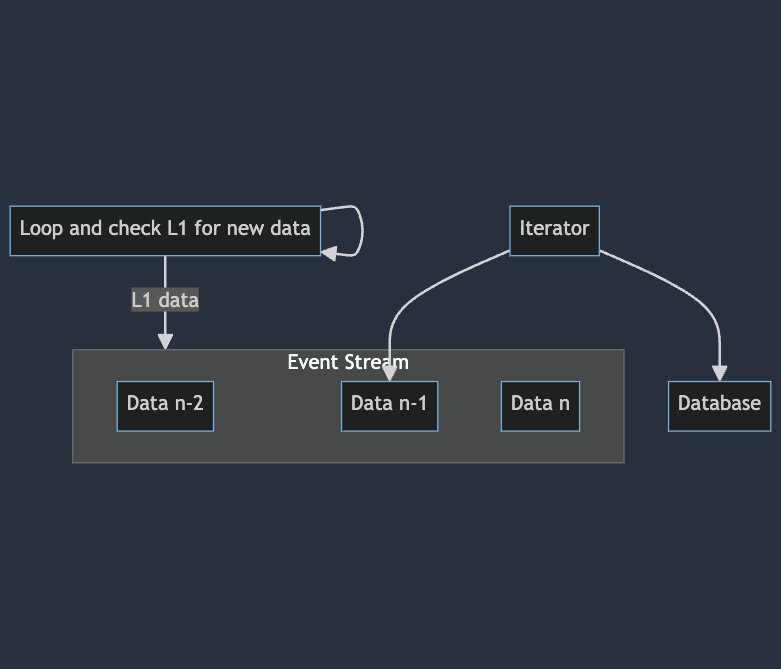
graph TD
A[Loop and check L1 for new data] -->|L1 data| EventStream
subgraph EventStream[Event Stream]
C[Data n-2]
D[Data n-1]
E[Data n]
end
F[Iterator] --> D
F --> G[Database]
A --> A
Then, when queries about the latest state (like a "what is my token balance?") or blockchain data (like "what is inside block 100?") or come in, a separate RPC server queries this database and responds to the request. It does this by triggering specific functions whenever an HTTP (or WS, gRPC, etc.) request comes in.
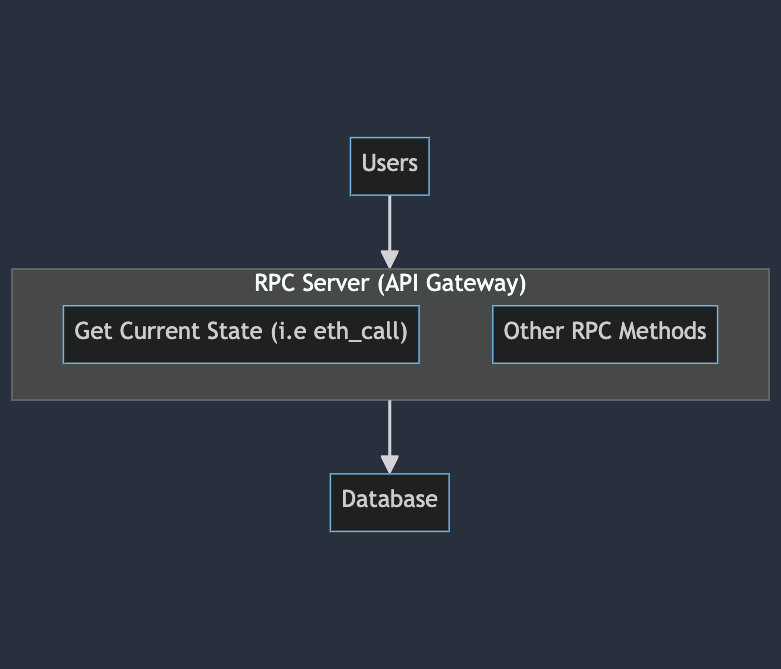
graph TD
Users[Users] --> RPCServer --> Database[Database]
subgraph RPCServer["RPC Server (API Gateway)"]
A["Get Current State (i.e eth_call)"]
B[Other RPC Methods]
end
This architecture actually leads to a lot of problems
- Duplicative data storage. For the most part, the data is already on the L1. A lot of this is then copied over into the rollup's DB. This works on a scale of n=1, but can be a headache for infrastructure providers like Modular Cloud.
- Missing information. What was the state diff? The error logs? The execution trace? The historical state? The node rarely provides good tools for retrieving this.
- DevOps challenges. Running nodes at scale is non-trivial and expensive. You have to maintain long-running processes that autoscale with high storage requirements.
Functional execution mode
💡 The functional execution mode should be available alongside the conventional implementation described above. With that said, I imagine rollup teams would benefit from first conceptualizing their rollup functionally, and then building the conventional system as a wrapper around it.
The fundamental problem is that we don't control how and when the state transition function this is executed.
For example, as an infrastructure provider, if I already know when new "Data n+1" is coming in—why do I need to keep a long running process that monitors this? I should be able to trigger this on my own terms. This may not seem like a big deal, but it matters at scale.
The solution is for rollup developers to support a canonical way of running the state transitions and queries as pure functions—such that there can be full control over the inputs, as well as observability into the outputs and execution paths. I call this a functional execution mode, as opposed to bundling all of these functions inside of a long-running, inflexible node implementation.
On a practical level, there is simple way of framing this. Ideally, anyone can take the core state transition function, and "bring their own" event stream, database, and API gateway.
Bring-Your-Own-Events
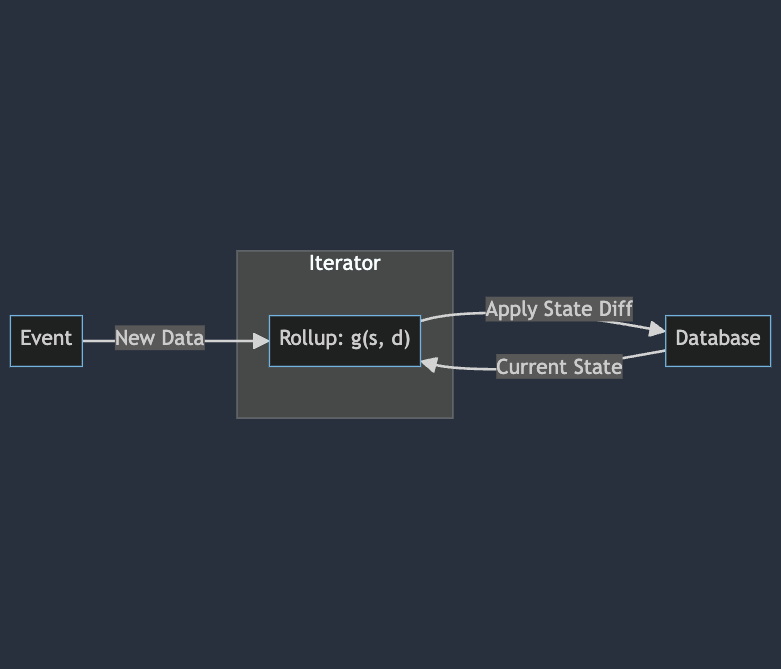
graph LR
Event -->|New Data| rollup["Rollup: g(s, d)"] -->|Apply State Diff| Database
subgraph Iterator
rollup
end
Database -->|Current State| rollup
An infrastructure provider should be able to listen to events on the DA layer and trigger the state transition function of the rollup on-demand. It is important to note that, instead of serializing the current state (s) and passing it into the function g(s, d) , this should actually be implemented as a function g(d) that takes the new data as a parameter and has access to a database (as described in the next section). This is likely the best implementation because the state of a rollup could be too large to be stored in memory.
Bring-Your-Own-Database
A good example of this is Tendermint's tm-db. There should be a clean interface that the rollup uses to read and write to the database, such that a third-party can swap out databases without worrying that the rollup will break. We can call this an "adapter". Ideally, this is an abstraction on top of a simple KV database. If the rollup depends on complex DB features, infrastructure providers will have less options for how to run and scale it.
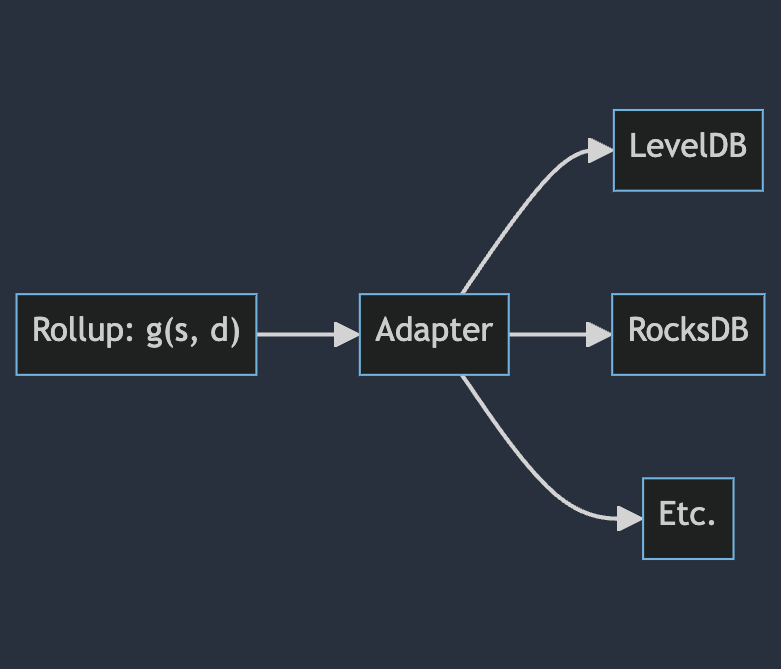
graph LR
rollup["Rollup: g(s, d)"] --> Adapter
Adapter --> LevelDB
Adapter --> RocksDB
Adapter --> other[Etc.]
Although it is perfectly reasonable to store blocks and transactions in the database, in order for the node's built-in RPC server to respond to queries about blockchain data—it is important to emphasize that such data should not be considered state. It should be possible to run the rollup without storing blocks and transactions. The state transition function should simply need new data from the DA layer as well as access to a database with the current state.
Bring-Your-Own-Gateway
The RPC, or other built-in APIs, should be stateless functions that can run in a standalone manner by reading from the database adapter.
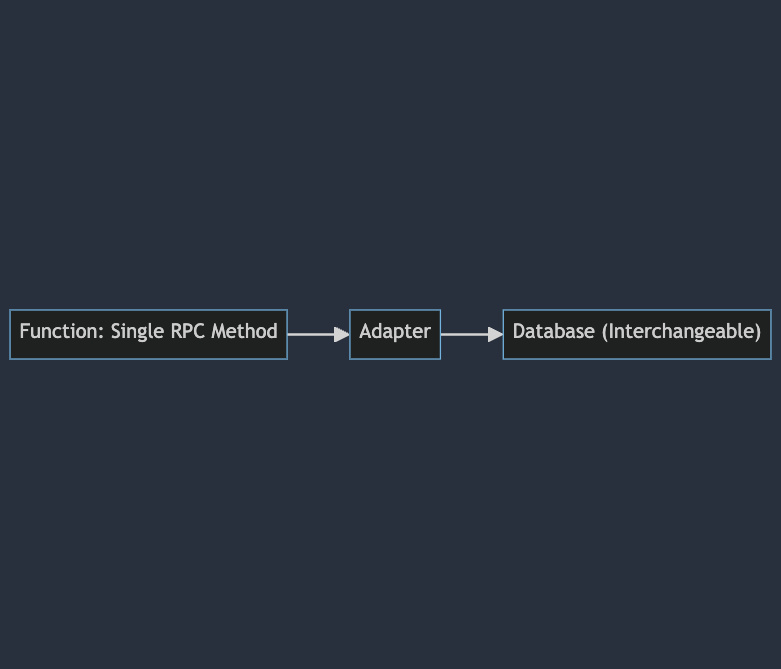
graph LR
RPC[Function: Single RPC Method] --> Adapter --> Database["Database (Interchangeable)"]
This should resemble a simple lambda function that connects to an up-to-date database, performs some queries and computations, and then returns the response to the query.
Why?
These patterns cause significant benefits.
- This can greatly reduce storage costs for infrastructure providers. I won't go into this too deeply, but essentially this allows the state and data of a rollup to be calculated on-demand instead of requiring costly pre-indexing. This is a huge optimization for servicing less popular, long-tail rollups.
- This gives infrastructure providers insight into state diffs, execution traces, and logs, since they have more control over how the state transition function was run. For example, they can execute the function inside of a debugger to see a full trace.
- Since RPC calls can be executed serverlessly, this makes it trivial to performantly respond to queries about state or historical data at web2 scale.
- All of this is possible without any complicated DevOps, such as running nodes, indexers, containers, or other long-running instances.
Additional Context
Think about building cloud infrastructure to support tens of thousands of chains.
- Continuously running a node or indexer for each rollup uses a lot of compute time.
- Not running a node poses a platform risk for the cloud infrastructure provider, because they are dependent on another DevOps team for keeping the node online. With that said, sometimes rollup teams require everyone to use their single, hosted node.
- Even if the cloud provider is not running the node, they still need to run the indexer which is unsure of when a new block will be created. Therefore, it needs to continuously pull (or maintain an open connection) in order to have real-time capabilities.
- Pooling multiple nodes on a single machine is complex, because one bug can take down multiple chains.
- Storing all data from all chains requires a ton of storage.
- Since most rollups have poor long-term data storage guarantees, not storing data runs the risk that history will be lost.
- Cloud providers ought to be the chain archivers of last resort. This is especially important for long-tail (low-value, unpopular) chains. Centralized cloud storage can store more data at a lower cost than decentralized data storage networks because...
- Decentralized networks require more redundant storage than centralized storage.
- Centralized providers have economies of scale.
- The above points are not problems when users are running nodes that they are using themselves (the traditional use case of a node). Problems emerge when an infrastructure provider, or similarly positioned project, integrates with a large number of chains. Inefficiencies are amplified.
- The unfortunate effect of this is that many projects will refuse to integrate with less popular, long-tail chains—since the cost of doing so is higher than the expected profit.
- Some chains will have millions of daily requests, but autoscaling nodes is complex and has high fixed-costs.
- This might be controversial, but serverless is simply a superior way to scale.
- Autoscaling makes it difficult to take advantage of cloud-native systems, like edge compute.
- Cost attribution is difficult. How do you charge customers?
Cost per request = cost per node / max requests per node? This doesn't even take into account the fact that some requests take up more compute than others. - Synchronizing state is notoriously painful across multiple nodes in a cluster. With that said, it remains to be seen how much this impacts rollup users.
- Modifying nodes is not scalable.
- The original source of a node cannot be forked to make it more cloud-friendly. As a cloud infrastructure provider, maintaining thousands of forks of different rollups is untenable. Nodes must be run in a canonical manner, officially supported by the core team, to ensure they do not diverge from the real network.
- Additional context therefore cannot be exposed.
- For example, if the exact reference to the blob in the DA layer is not returned by the node (i.e. the share commitment, or transaction hash and blob index), the cloud provider cannot know for sure which blob corresponds to what data in the rollup.
- If the rollup does not have a method like eth_replayTransaction, then there is no insight into state diffs or execution traces.
How this solution solves these problems
- Rollup compute would only be triggered when relevant L1 data is detected.
- Long-tail rollups do not need to be executed until someone requests data from them (very infrequently).
- Since all rollup state and historical data can be deterministically generated by replaying the L1, data can expire (or never be stored) without fear of loss.
- Since you can store and load checkpoints into the state transition function, you can reduce storage by orders of magnitude without sacrificing too much performance (the whole chain does not need to replay).
- By using a cloud-native database, indexing and synchronization issues are automatically solved.
- RPC calls can run serverlessly, potentially at edge, infinitely scale, and provide better cost attribution context.
- State diffs can be captured from DB writes, execution traces can be generated by running the state function in a debugger, and logs can be captured by a cloud-native log system.
- This data is useful in many contexts. For example, people may want to see this in a block explorer.
- Some other use cases:
- State diffs can be used to build event systems on top of state changes, which can be used for
- Performance optimizations (pre-caching balances and other state queries)
- Implementing event driven app features like balance change notifications
- Execution traces can be useful for simulation and event based dev tools
- State diffs can be used to build event systems on top of state changes, which can be used for
- Since the functional execution mode would be officially supported the rollup core team, it would not require modification of the node's source.